|
I am currently a postdoctoral researcher at the
Visual Geometry Group (VGG), University of Oxford,
advised by Professor Andrew Zisserman.
Before that, I received my Ph.D. degree from Fudan University, where I was advised by
Professor Yuejie Zhang.
I also collaborate closely with Professor Weidi Xie at Shanghai Jiao Tong University.
My research interests include multimodal video understanding,
visual representation learning, and
medical image analysis.
I aspire to contribute to building medical AI agents that can heal the world
and make it a better place for all humankind.
Google Scholar /
Twitter /
GitHub /
Zhihu
|

|
📢 News
|
📑 Research |
|
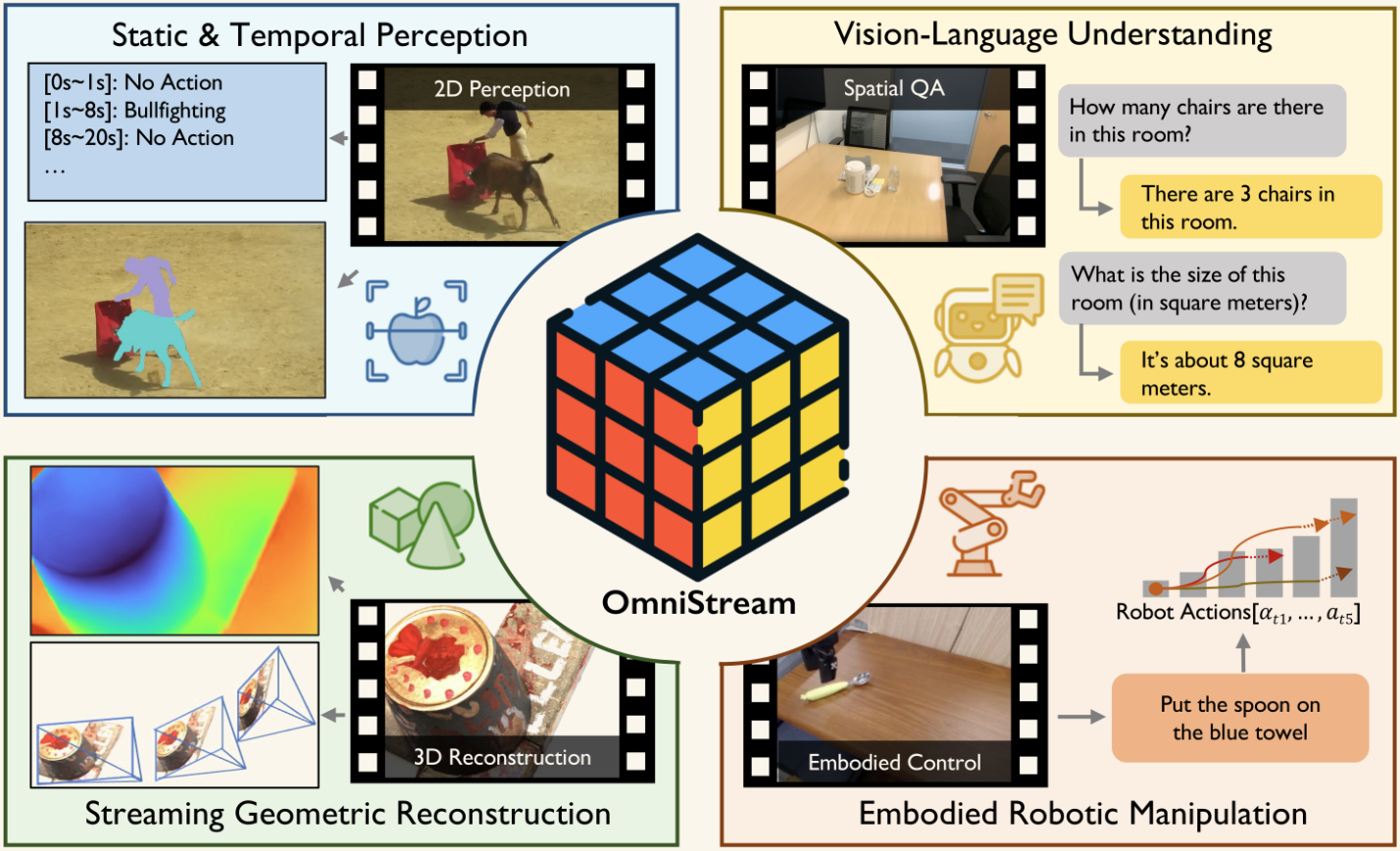
OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
Technical Report
OmniStream is a unified streaming visual backbone that effectively perceives, reconstructs, and acts from diverse visual inputs, supporting visual probing, streaming geometric reconstruction, VLM and VLA. |
|
Scaling Audio-Text Retrieval with Multimodal Large Language Models
Technical Report
AuroLA is a contrastive language-audio pre-training framework that re-purposes Multimodal Large Language Models as a unified backbone for retrieval. |
|
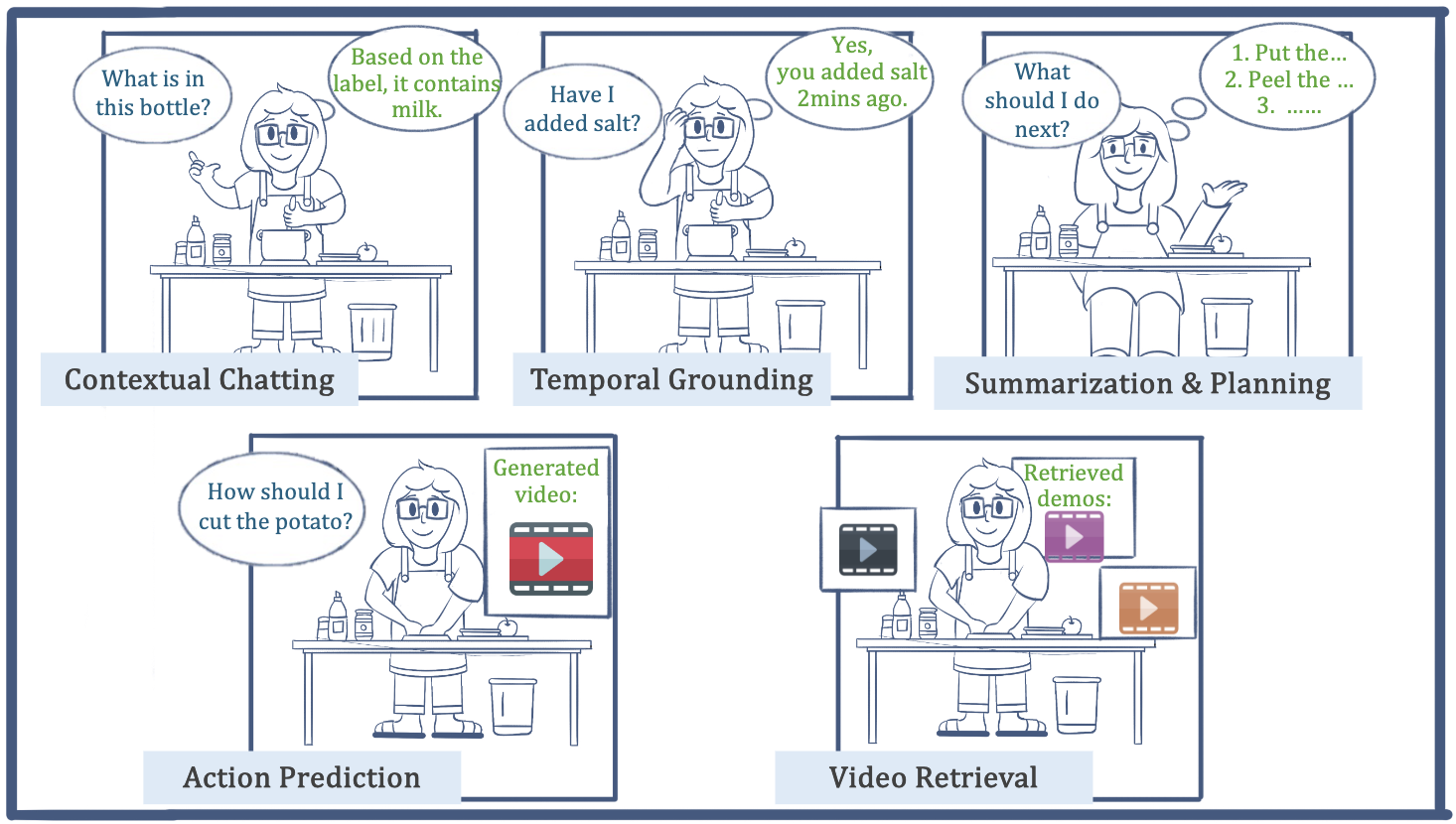
Vinci: A Real-time Smart Assistant Based on Egocentric Vision-language Model for Portable Devices
IMWUT 2025
A real-time vision-language system that can assist users with daily tasks, including scene understanding, grounding, summarization, and future planning. |
|
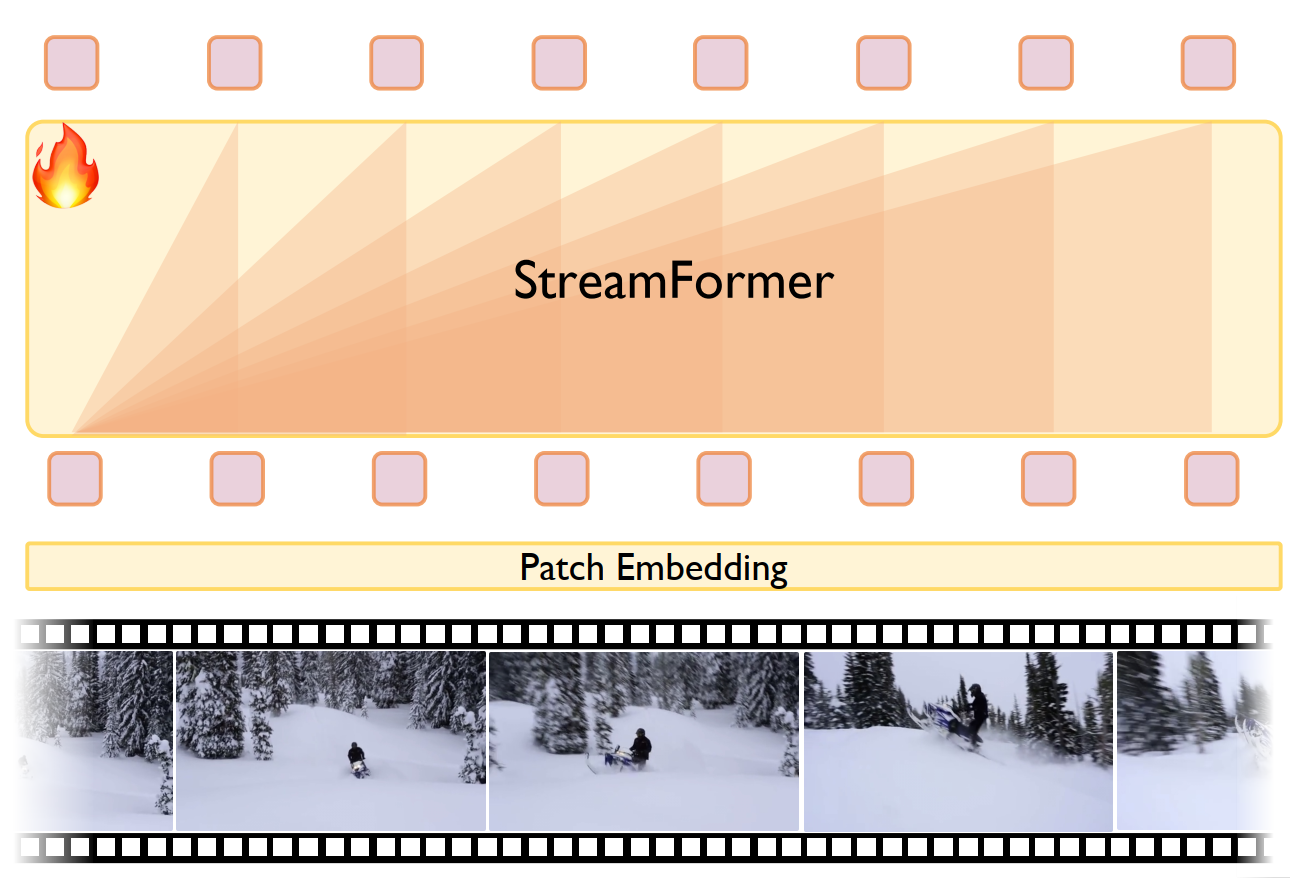
Learning Streaming Video Representation via Multitask Training
ICCV 2025, Oral
A streaming video backbone that learns global, temporal, and spatial video features in a unified visual-textual alignment framework. |
|
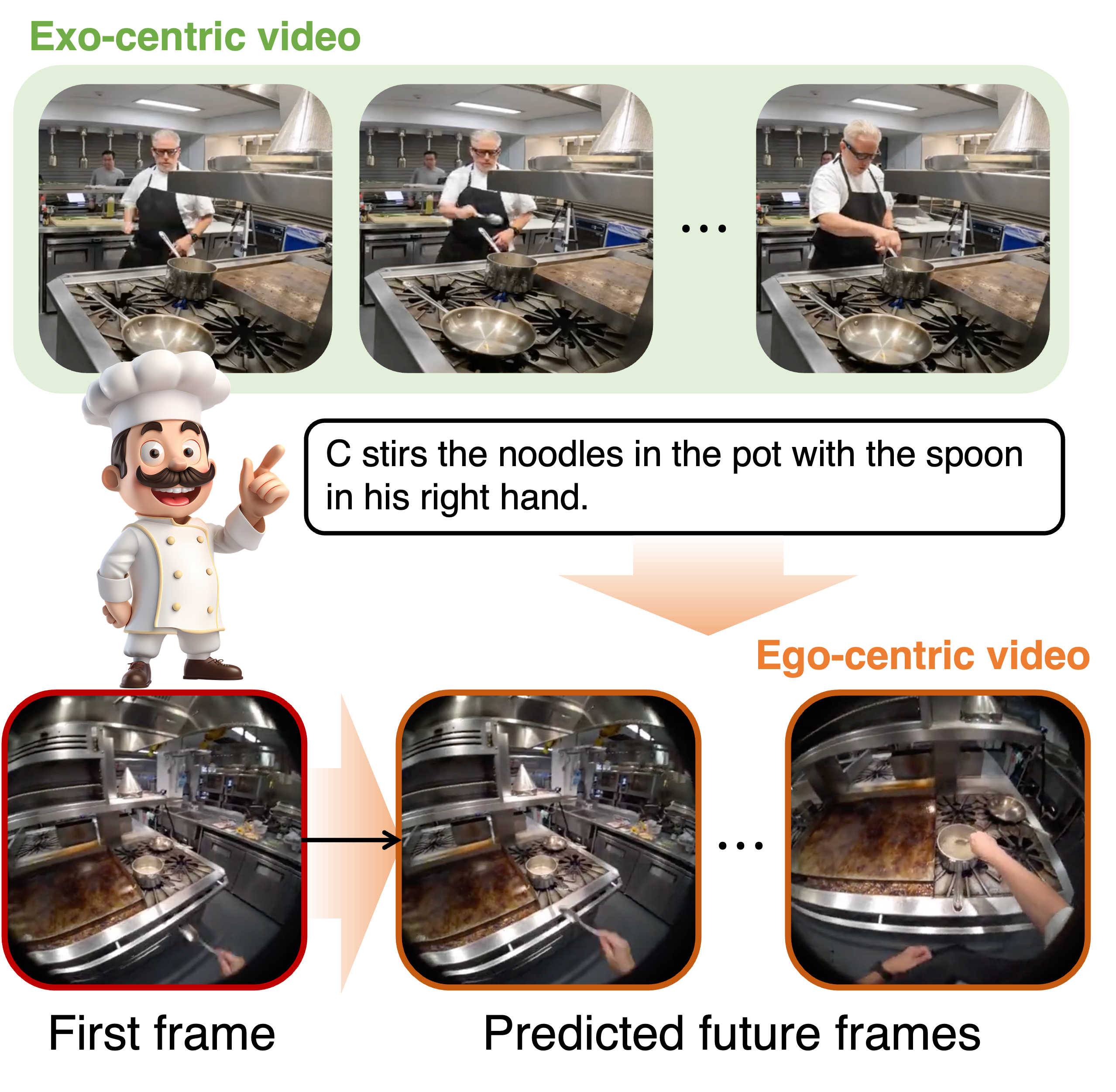
EgoExo-Gen: Egocentric Video Prediction by Watching Exocentric Videos
ICLR 2025
A cross-view video prediction model that predicts future egocentric video frames by leveraging paired exocentric video and text instructions. |

|
EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
CVPR 2024
A cross-view benchmark dataset that emulates the human demonstration following process, containing recorded egocentric videos guided by exocentric-view demonstration videos. |
|
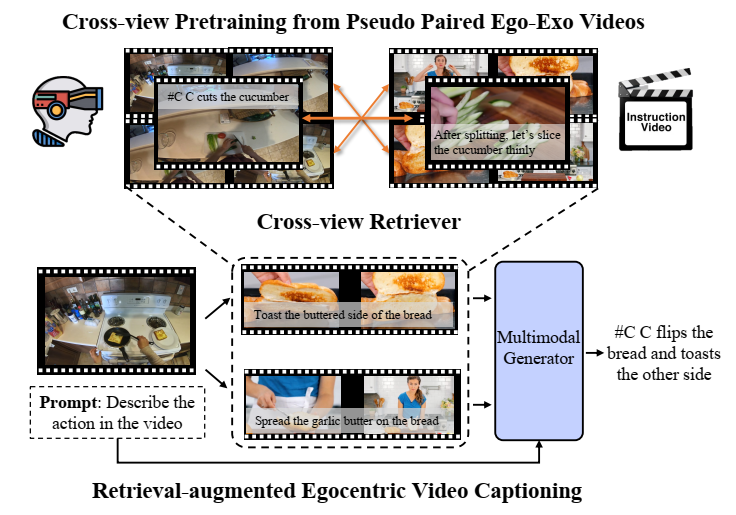
Retrieval-Augmented Egocentric Video Captioning
CVPR 2024
Given an egocentric video, Egoinstructor automatically retrieves relevant exocentric instructional videos for assisting egocentric video captioning. |
|
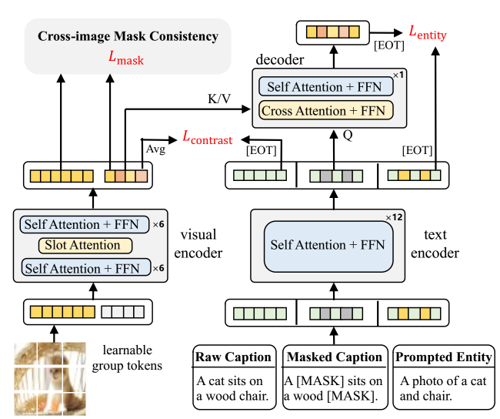
Learning Open-vocabulary Semantic Segmentation Models From Natural Language Supervision
CVPR 2023
Training open-vocabulary semantic segmentation models with image-text pairs only, which enables zero-transfer to various segmentation datasets. |
|
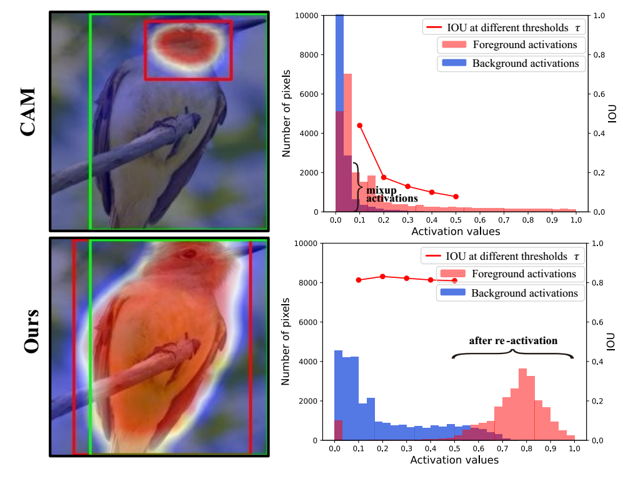
CREAM: Weakly supervised object localization via class re-activation mapping
CVPR 2022
A weakly-supervised object localization model that generates better CAMs via soft-clustering algorithms. |
|
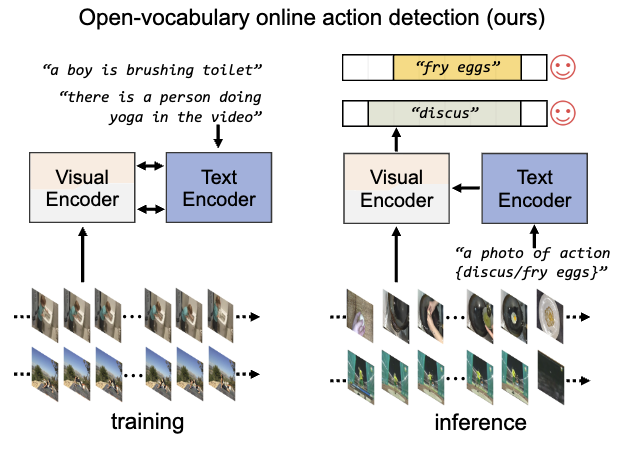
Does video-text pretraining help open vocabulary online action detection
NeurIPS 2024
A zero-shot online action detector that leverages vision-language models and enables open-world temporal understanding. |
|
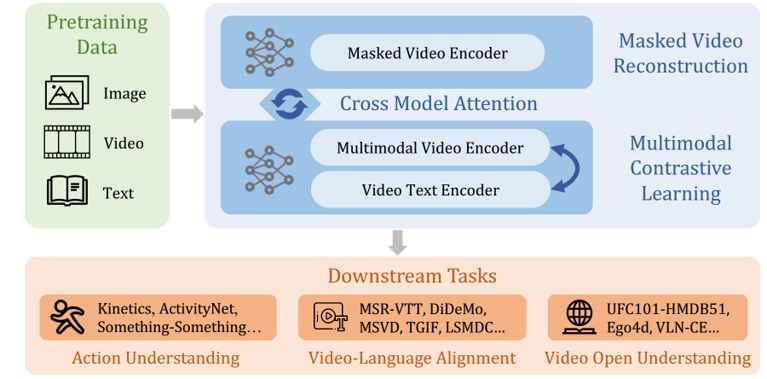
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Tech report 2022
A foundation model for video / video-text understanding, achieving SOTA over 30 benchmark datasets. |
|
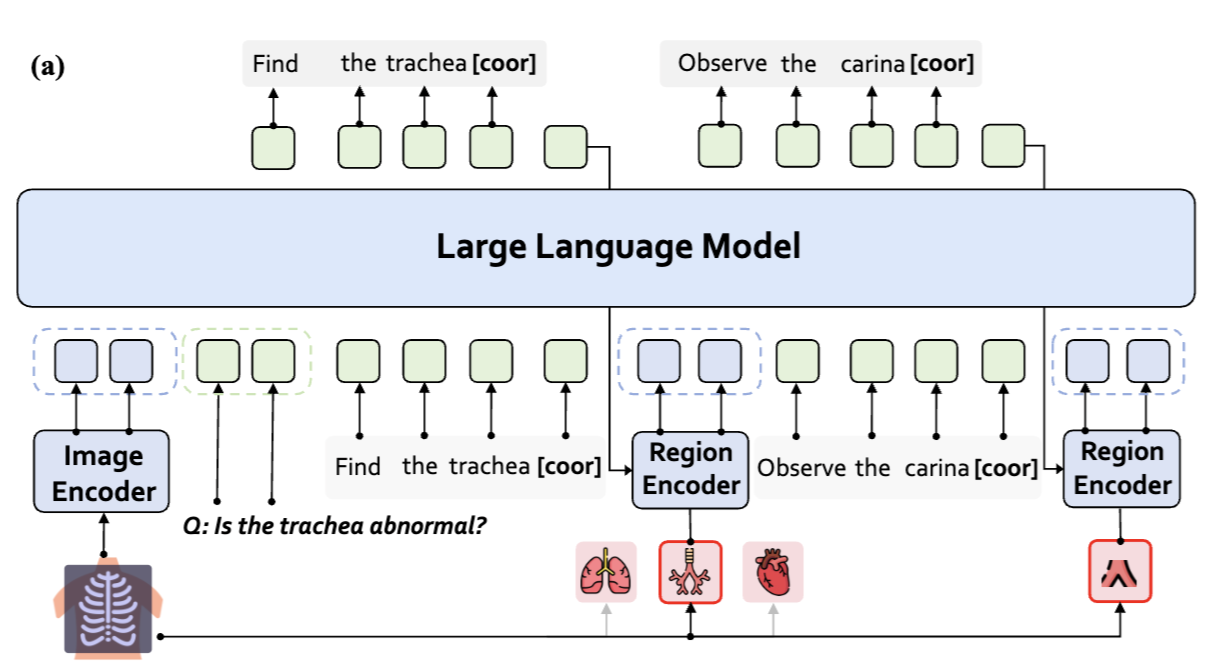
AOR: Anatomical Ontology-Guided Reasoning for Medical Large Multimodal Model in Chest X-Ray Interpretation
NeurIPS 2025
An anatomical ontology-guided reasoning model and a large instruction dataset for chest-x-ray image understanding. |
|
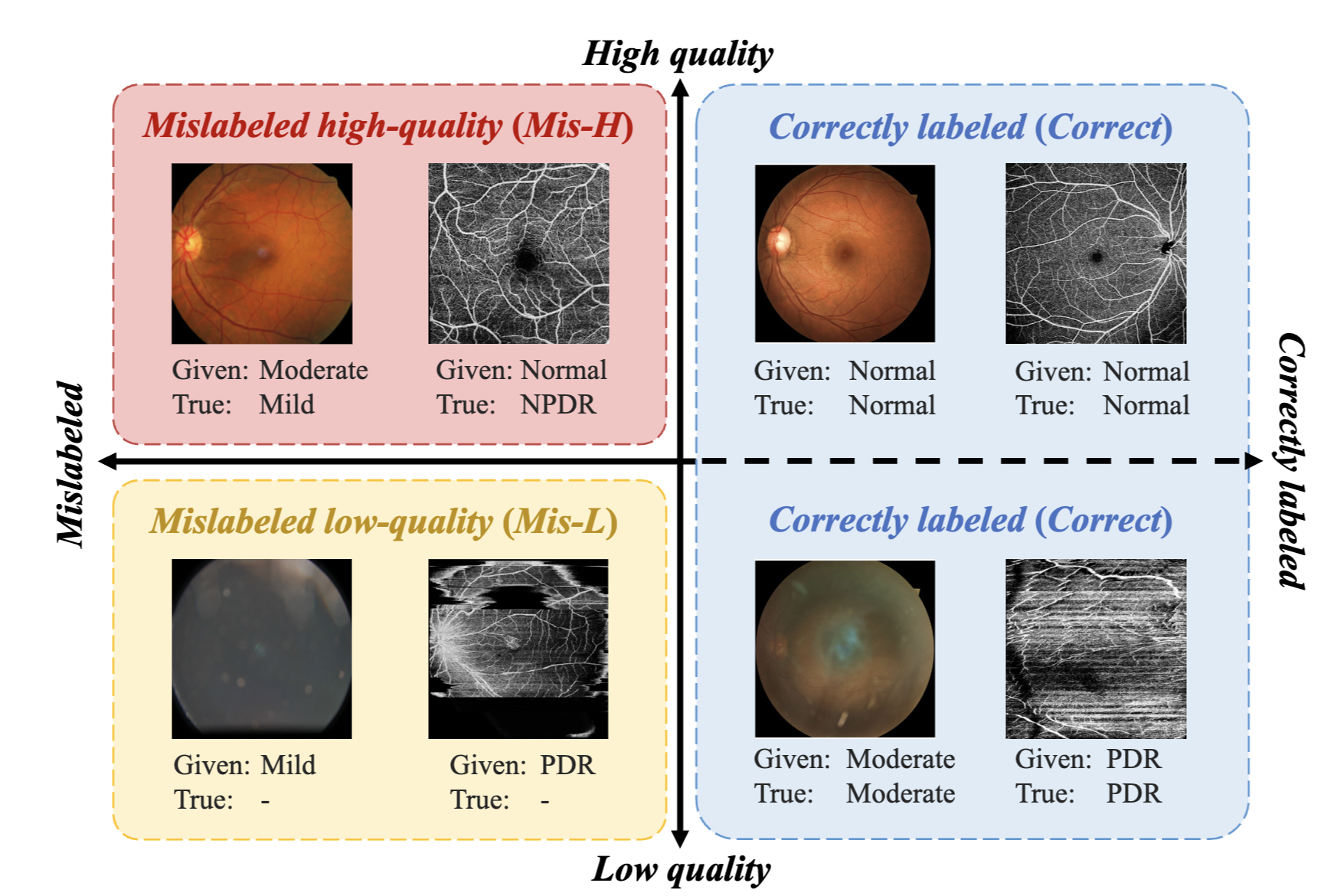
QMix: Quality-aware Learning with Mixed Noise for Robust Retinal Disease Diagnosis
IEEE Transactions on Medical Imaging 2025
A noise learning framework that learns a robust disease diagnosis model under mixed noise scenarios. |
|
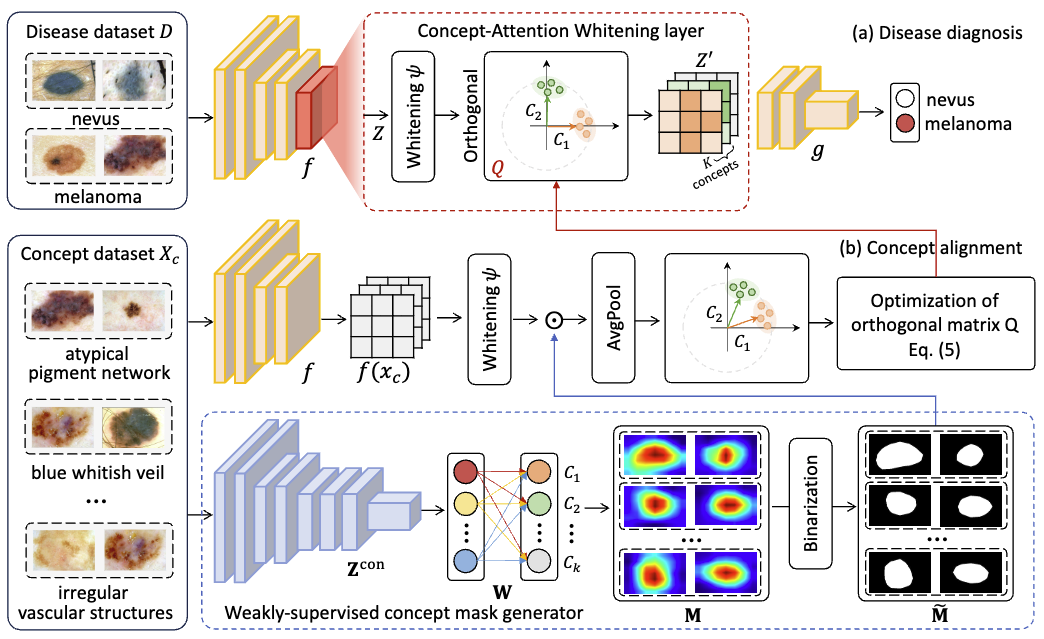
Concept-Attention Whitening for Interpretable Skin Lesion Diagnosis
MICCAI 2024
An XAI framework that aligns the axes of the latent space with concepts of interest for interpretable skin lesion diagnosis. |
|
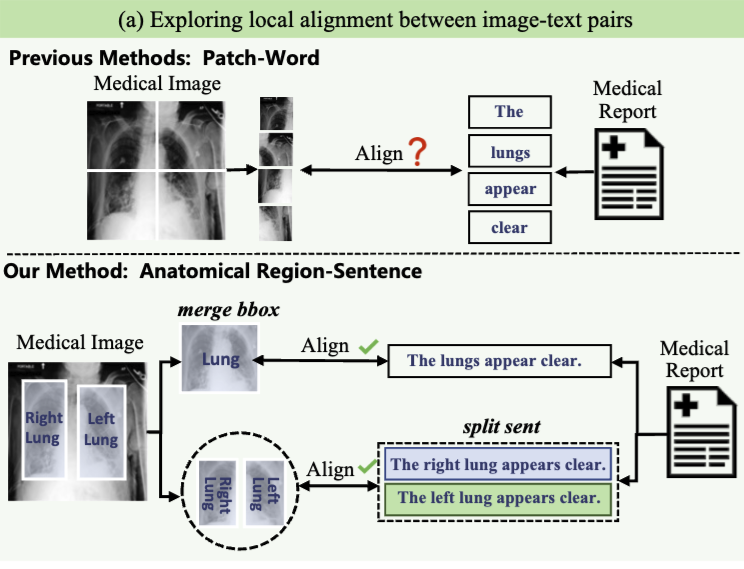
Anatomical structure-guided medical vision-language pre-training
MICCAI 2024
An Anatomical Structure-Guided visual-text pre-training framework that leverages the anatomical knowledge. |
|
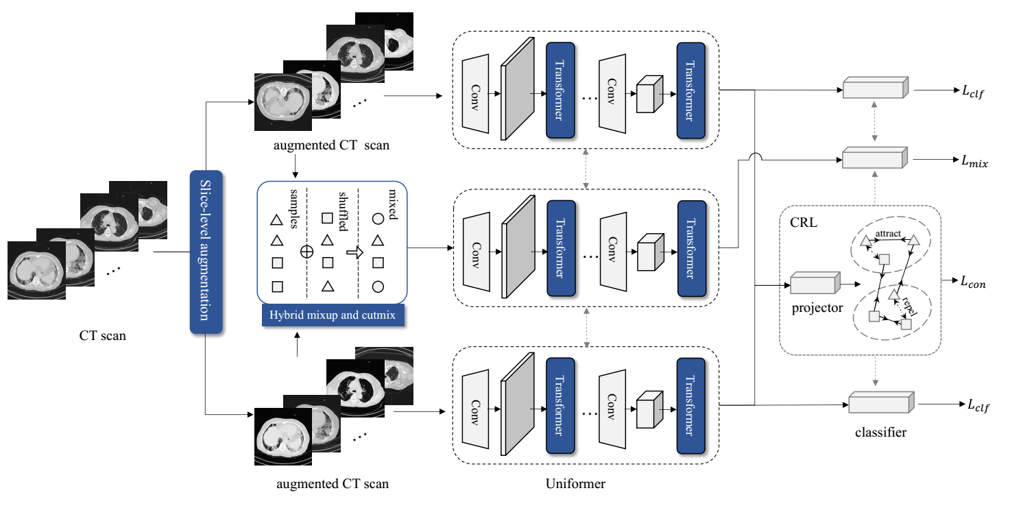
CMC_v2: Towards More Accurate COVID-19 Detection with Discriminative Video Priors
ECCV 2022 AIMIA Workshop
A Transformer-based model with contrastive representation enhancement. Winner of the 2nd COVID-19 Detection in ECCV 2022. |
|
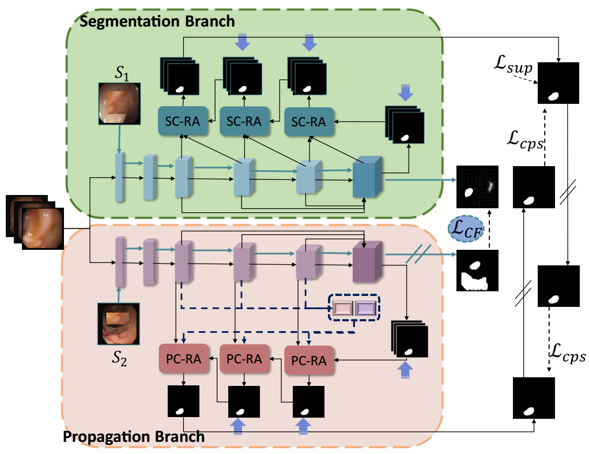
TCCNet: Temporally Consistent Context-Free Network for Semi-supervised Video Polyp Segmentation
IJCAI 2022, Oral
Co-training a model for semi-supervised video polyp segmentation, achieving comparable results using only 15% labeled data. |
|
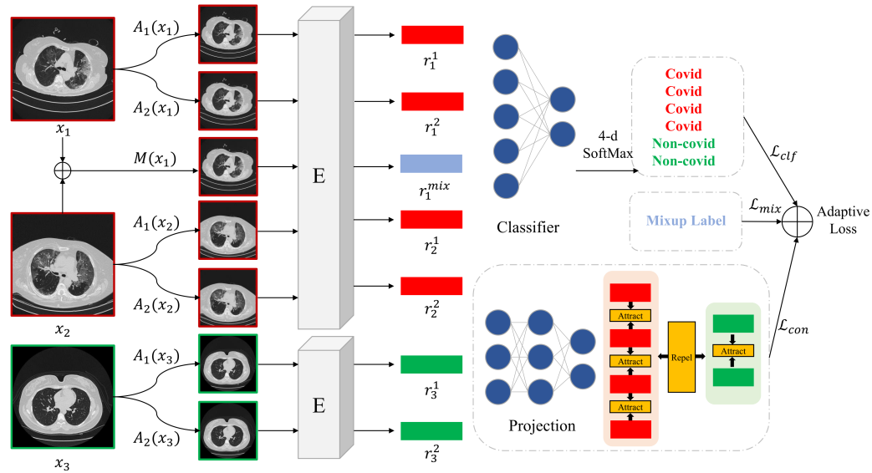
CMC-COV19D: Contrastive Mixup Classification for COVID-19 Diagnosis
ICCV 2021, AIMIA Workshop
A ResNest-50 model combined with contrastive mixup technique for 3D COVID-19 CT image classification. Winner of the 1st COVID-19 detection challenge. |
|
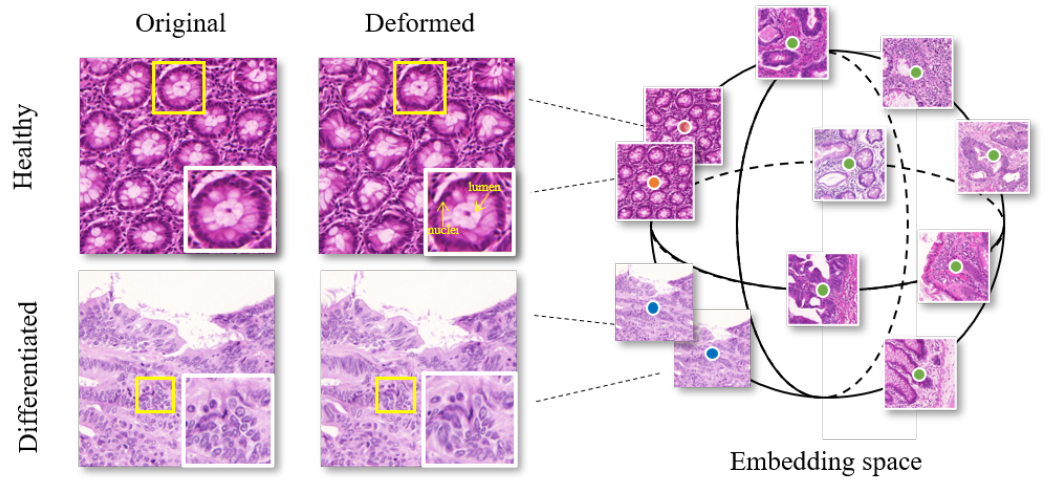
Data-Efficient Histopathology Image Analysis with Deformation Representation Learning
BIBM 2020, Oral
Introducing a self-supervised deformation representation learning technique for histopathology image analysis. |
🏆 Awards & Honors
|
💼 Working ExperienceShanghai AI Laboratory
Research Intern
Supervised by Dr. Yifei Huang, Yi Wang and Prof. Yu Qiao
Bell AI Lab, Shanghai
Research Intern
Supervised by Dr. Chenhui Ye
Google Winter AI Camp
🏆 Best Presentation Award
Morgan Stanley Technology
Software Engineering Intern
Supervised by Ray Zhou
|
🎓 Academic ServicesGuest Editor
Journal of Imaging (IF=3.3)
Conference Reviewer
ICLR26/25, NeurIPS25/24/22, ECCV26/24, MICCAI25/24, CVPR25/24/23, ICCV25/23, ACMMM25, ICML26/25, SIGIR26
Journal Reviewer
Nature Communications, TPAMI, IJCV, TMM, NeuroComputing
Teaching Assistant (TA)
Data Structure, The Theory of Computation
|
|
This guy is good at website design. |